Protección de las aplicaciones API de Amazon: retención y recuperación de datos
Establezca procedimientos de retención y recuperación de datos para ayudar a garantizar el acceso a los datos y reducir la exposición de los datos.
Abstracto
Es importante proteger la confianza del cliente manteniendo los datos seguros. Las razones fundamentales para tener políticas de retención de datos no han cambiado a lo largo de los años, pero la evolución de la tecnología, los requisitos reglamentarios y los panoramas de amenazas agregan complejidad.
Los diferentes tipos de datos requieren varios tiempos de retención, lo que complica el equilibrio entre mantener los datos fácilmente disponibles para su uso y también cumplir con los requisitos legales, comerciales y personales. Establecer procedimientos de retención y recuperación de datos ayuda a garantizar que el acceso a los datos, como la información de identificación personal (PII), esté disponible durante el tiempo que sea necesario para operar el negocio y, al mismo tiempo, reducir el riesgo de exposición de datos.
Requisitos de la política de protección de datos
Como se indica en la Política de protección de datos de la API de Amazon Services :
Los desarrolladores conservarán la PII por no más de 30 días después de la entrega del pedido y solo con el propósito de (i) cumplir con los pedidos, (ii) calcular y remitir impuestos, (iii) generar facturas de impuestos y otros documentos requeridos, y (iv) cumplir con los requisitos legales, incluidos los requisitos fiscales o reglamentarios. Los desarrolladores pueden conservar los datos durante más de 30 días después de la entrega del pedido solo si así lo exige la ley y solo con el fin de cumplir con esa ley. Según las secciones 1.5 ("Cifrado en tránsito") y 2.4 ("Cifrado en reposo") en ningún momento se debe transmitir o almacenar la PII sin protección.
Base de la retención y recuperación de datos
Mantener la privacidad de la PII de los clientes de Amazon es importante para garantizar la integridad de la identidad del comprador. Este tipo de información requiere protección porque puede usarse para marketing no solicitado, para cometer fraude o para robar la identidad de una persona. La eliminación de contenido que ya no se necesita reduce el riesgo de litigios y violaciones de seguridad.
Los desarrolladores pueden aprovechar el control NIST-800-53 SI-12: Gestión y retención de la información . La intención de este control es garantizar que la información, incluida la PII, se conserve de acuerdo con los requisitos reglamentarios, contractuales y comerciales.
Los desarrolladores también deben considerar todos los requisitos aplicables. Estos requisitos determinan el período de retención de la información, incluidos los casos más allá de la eliminación del sistema. Los desarrolladores aún pueden obtener información histórica según sea necesario para cumplir con sus obligaciones poniéndose en contacto con Amazon MWS y SP-API.
Los desarrolladores deben estar familiarizados con la siguiente terminología importante:
- La información de identificación personal (PII) es información que, cuando se usa sola o con otros datos relevantes, puede identificar a una persona.
- La retención de datos es el proceso de almacenamiento de datos por motivos comerciales o de cumplimiento.
- El período de retención de datos es la cantidad de tiempo que una organización almacena un tipo particular de datos. Los diferentes tipos de datos deben tener diferentes períodos de retención.
- El archivado es el proceso de mover datos que ya no se utilizan a un dispositivo de almacenamiento o ubicación independiente para su retención, preferiblemente almacenamiento en frío.
- El almacenamiento en frío es un medio de almacenamiento para datos inactivos y de acceso poco frecuente.
- La copia de seguridad es una copia de los datos hecha en caso de que algo le suceda al original. Cuando se aplica una política a esa copia de respaldo, se conoce como retención de datos de respaldo.
- La destrucción se define como la destrucción física o técnica de datos que los hace irrecuperables por medios ordinarios disponibles comercialmente.
Recopilación de datos
Antes de recopilar la PII de los clientes de Amazon, una organización debe determinar dos cosas:
- La necesidad comercial de PII del cliente.
- Quién debe tener acceso a los datos.
Los requisitos del desarrollador para la PII del cliente de Amazon deben cumplir con la Política de protección de datos de la API de Amazon Services .
Los desarrolladores están obligados a retener la PII de los clientes de Amazon solo durante el tiempo que sea necesario para cumplir con los pedidos o para calcular/remitir impuestos en nombre de los sellers. La PII de los clientes de Amazon no debe almacenarse en los sistemas de los desarrolladores durante más de 30 días después del envío del pedido.
Si la ley exige que un desarrollador conserve copias de la PII del cliente de Amazon con fines impositivos, legales o reglamentarios similares, esta información de Amazon se puede almacenar en un almacenamiento de respaldo en frío o fuera de línea en una instalación físicamente segura.
Todos los datos archivados en medios de respaldo deben estar encriptados. Tradicionalmente, esto requiere hardware costoso y especialmente diseñado y puede aumentar rápidamente los costos de almacenamiento a medida que aumenta el volumen de retención de datos. El uso de almacenamiento en la nube como Amazon Simple Storage Service Glacier (Amazon S3 Glacier) para el archivado a largo plazo permite a las organizaciones almacenar datos de manera rentable durante años o incluso décadas. Con este enfoque, las organizaciones pueden descargar la tarea administrativa de administrar y escalar el almacenamiento.
Si el uso del almacenamiento en frío no está en consonancia con los casos de uso comercial y los datos deben permanecer en producción, los desarrolladores deben asegurarse de que la información PII obtenida a través de Amazon MWS y SP-API que se retiene y transmite a través de los sistemas del desarrollador esté cifrada en todo momento.
Los desarrolladores también deben asegurarse de que solo el personal autorizado tenga acceso a estos datos. Consulte Protección de aplicaciones API de Amazon: Cifrado de datos para obtener más información sobre el cifrado.
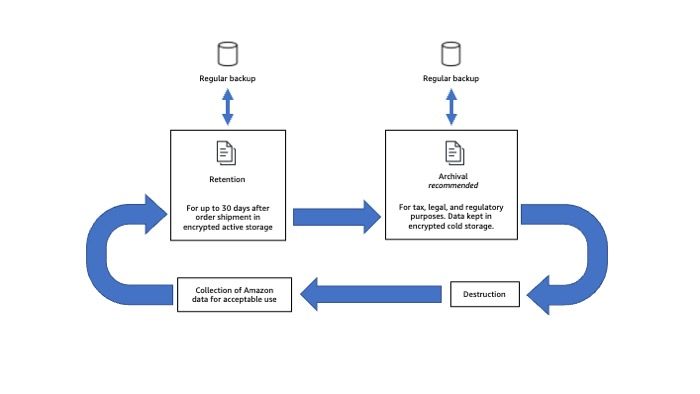
Figura 1: procesamiento de datos de Amazon
Retención
Al crear o revisar un plan de retención de datos, los desarrolladores deben:
- Cree una política de retención de datos. Esta política debe cumplir con la Política de protección de datos de Amazon y debe cumplir con los requisitos legales del desarrollador.
- Automatice las tareas de retención de datos . Esto debe hacerse de tal manera que las tareas se puedan cambiar fácilmente a medida que cambian los requisitos. Amazon S3 Glacier es un ejemplo de un archivo basado en la nube que puede archivar datos automáticamente según una política. Para obtener más información sobre Amazon S3 Glacier, consulte la sección Archivado .
- Considere si los datos deben archivarse o eliminarse . La eliminación es permanente, pero el archivo genera costos de funcionamiento. Implemente diferentes ciclos de vida para diferentes tipos de datos y casos de uso. Por ejemplo, el cumplimiento tiene diferentes requisitos legales y comerciales que los casos de uso de impuestos.
- Elimine la información de Amazon cuando ya no sea necesaria o ya no esté sujeta a otras obligaciones de retención.
- Mantenga informados a los sellers de Amazon sobre las prácticas de retención de datos que sigue y la base sobre la cual los sellers deben acceder y procesar la PII de los clientes de Amazon.
- Realice copias de seguridad y asegure la información de Amazon en todo momento. Esto debe hacerse de acuerdo con las políticas de Amazon MWS y SP-API. Esto es importante para la retención de datos y la gestión de datos en general.
Archivar
Cuando sea necesario conservar la información de Amazon por motivos normativos o de cumplimiento, los desarrolladores deben archivar la información siempre que sea posible. A diferencia de la creación de una copia de seguridad, que consiste en mantener una copia de los datos de producción durante un breve período de tiempo para recuperarse de la corrupción o pérdida de datos, el archivado mantiene todas las copias de los datos hasta que vence la política de retención.
Un buen sistema de archivo tiene las siguientes características:
- Durabilidad de los datos para una integridad a largo plazo
- Seguridad de datos
- Facilidad de recuperabilidad
- Bajo costo
Los desarrolladores que utilizan NIST 800-53 como marco pueden consultar el control MP-4: Media Storage . Si bien este control es parte del dominio Media Protection (MP), los desarrolladores de Amazon MWS y SP-API deben archivar y almacenar la información archivada en una copia de seguridad cold o fuera de línea alojada en una instalación físicamente segura. MP-4 requiere específicamente la protección de los medios mediante el control físico y el almacenamiento seguro de los medios, así como la eliminación correcta de los medios. Los desarrolladores pueden mejorar aún más este control al implementar la protección criptográfica como se describe en SC-28(1). Considere aprovechar las opciones de almacenamiento en frío en las nubes públicas para cumplir con los requisitos de este control.
Archivado de datos con Amazon Web Services (AWS)
Amazon Simple Storage Service Glacier (Amazon S3 Glacier) es una solución segura, duradera y económica para archivar datos y hacer copias de seguridad a largo plazo. Además, proporciona cifrado nativo de datos en reposo, 99,999999999 % (11 nueves) de durabilidad y capacidad ilimitada. Los clientes de Amazon S3 Glacier pueden almacenar datos por tan solo $1 por terabyte por mes. Amazon S3 Glacier también ofrece tres opciones para acceder a los archivos, con tiempos de recuperación que van desde milisegundos hasta unos pocos minutos y varias horas.
Amazon S3 Standard-Infrequent Access es una buena opción para casos de uso que requieren una recuperación rápida de datos. Amazon S3 Glacier es una buena opción para casos de uso en los que se accede a los datos con poca frecuencia y los tiempos de recuperación de varias horas son aceptables.
Los objetos se organizan en niveles en Amazon S3 Glacier a través de reglas de ciclo de vida en Simple Storage Service (Amazon S3) o la API de Amazon S3 Glacier. La función de bloqueo de bóveda de Amazon S3 Glacier permite a los usuarios implementar y aplicar fácilmente controles de cumplimiento para bóvedas individuales de Amazon Glacier con una política de bloqueo de bóveda. Los desarrolladores pueden especificar controles como escritura única, lectura múltiple (WORM) en una política de bloqueo de bóveda y bloquear la política para futuras ediciones.
A continuación se muestra una representación visual de cómo se pueden utilizar los productos de AWS para satisfacer los requisitos de retención y recuperación de datos:
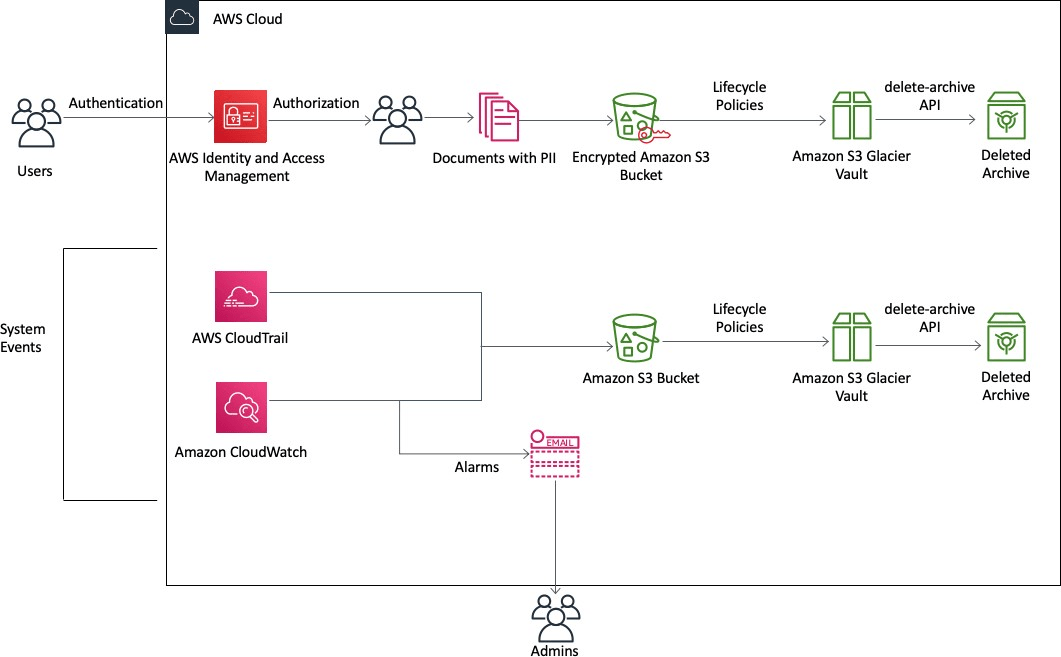
Figura 2: Archivo de datos usando AWS
En la figura anterior, los usuarios acceden a la nube de AWS a través de la autenticación y luego cargan documentos que contienen PII en un depósito cifrado de Amazon S3. Las políticas de ciclo de vida se pueden usar para cambiar automáticamente los datos del depósito de Amazon S3 a una bóveda de Amazon S3 Glacier. Una vez que la información ya no es necesaria para fines normativos, se llama a la API de archivo y eliminación de Amazon S3 Glacier para eliminar la información.
Además, AWS CloudTrail y AWS CloudWatch están habilitados para registrar acciones en el entorno y notificar a los administradores por correo electrónico si ocurre un evento. Los registros, almacenados en depósitos de Amazon S3, también están sujetos a políticas de ciclo de vida. Esto ayuda a eliminar costos de almacenamiento innecesarios.
Para obtener más información, consulte Qué es Amazon S3 Glacier y Configure un archivo compatible .
Escenario híbrido
Esta sección es para desarrolladores que usan un entorno híbrido grande. Supongamos que un desarrollador administra un entorno utilizado para realizar copias de seguridad de instancias de Amazon EC2, servidores independientes, máquinas virtuales y bases de datos.
Este entorno tiene 1.000 servidores. Se realiza una copia de seguridad del sistema operativo, los datos de archivo, las imágenes de la máquina virtual y las bases de datos. Hay 20 bases de datos (una mezcla de MySQL, Microsoft SQL Server y Oracle) para respaldar. El software de respaldo tiene agentes que respaldan sistemas operativos, imágenes de máquinas virtuales, volúmenes de datos, bases de datos de SQL Server y bases de datos de Oracle (usando RMAN).
Para aplicaciones como MySQL para las que el software de respaldo no tiene un agente, la utilidad de cliente mysqldump se puede usar para crear un archivo de volcado de base de datos en el disco. Los agentes de copia de seguridad estándar pueden proteger los datos.
Para proteger este entorno, el software de copia de seguridad de terceros en uso puede tener un servidor de catálogo global o un servidor maestro que controle las actividades de copia de seguridad, archivado y restauración, así como varios servidores de medios. Este servidor se puede conectar a almacenamiento basado en disco, unidades de cinta Linear Tape-Open (LTO) y servicios de almacenamiento de AWS.
Para aumentar esta solución de copia de seguridad con los servicios de almacenamiento de AWS, los desarrolladores deben considerar utilizar un vendor de copias de seguridad que utilice Amazon S3 o Amazon S3 Glacier. Amazon sugiere trabajar con los vendors para comprender sus opciones de integración y conectores. Para obtener una lista de vendors de software de copia de seguridad que trabajan con AWS, consulte el directorio de partners de AWS .
Si el software de copia de seguridad existente no admite de forma nativa el almacenamiento en la nube para realizar copias de seguridad o archivar, puede utilizar un dispositivo de puerta de enlace de almacenamiento. Esta puerta de enlace de almacenamiento actúa como un puente entre el software de copia de seguridad y Amazon S3 o Amazon S3 Glacier. Hay muchas soluciones de puerta de enlace de terceros disponibles para conectar los dos medios de almacenamiento, consulte el directorio de partners de AWS .
Si decide optar por una solución de AWS, los dispositivos virtuales de AWS Storage Gateway son un ejemplo de una solución de este tipo que se utiliza para cerrar esta brecha porque utiliza técnicas genéricas como volúmenes basados en iSCSI y bibliotecas de cintas virtuales (VTL). Esta configuración requiere un hipervisor compatible (VMware o Microsoft Hyper-V) y almacenamiento local para alojar el dispositivo.
Destrucción
Para eliminar datos correctamente, los desarrolladores deben eliminarlos de los almacenes de datos en vivo, así como de las copias de seguridad u otras copias. Esto significa que los desarrolladores deben configurar un mecanismo de retención adecuado en estas copias de seguridad y copias adicionales que esté en línea con su propósito comercial. La anonimización de datos no se considera un método aceptable para la eliminación de información de Amazon. Por ejemplo, codificar la PII del cliente de Amazon para anonimizarla en los almacenes de datos no es una alternativa aceptable para eliminar la información de Amazon.
Criterios de destrucción de datos de Amazon
En esta sección se analizan los criterios mínimos que requiere Amazon para que los datos se consideren eliminados de forma segura.
Caso 1 – Gestión directa de datos
Para mantener la coherencia con los estándares de la industria al administrar datos directamente (por ejemplo, almacenar datos en una instancia en lugar de usar el servicio en la nube para el almacenamiento persistente), los desarrolladores deben hacer las siguientes tres cosas para garantizar que los datos se eliminen de forma segura:
- Asegúrese de que los datos no sean recuperables por el cliente. Esto incluye a través de una API u otros mecanismos existentes que se pueden usar para acceder a los datos.
- Desasocie lógicamente los datos (por ejemplo, mediante la eliminación de punteros o la desvinculación de archivos de índice (inodos) a los datos). Esta acción comúnmente se superpone con el primer criterio.
- Marque el espacio multimedia que contiene los datos eliminados que el servicio reasignará.
Caso 2: uso de un servicio en la nube
Cuando se utiliza un servicio como Amazon S3 o Amazon DynamoDB para administrar datos, el servicio debe llamar a un mecanismo de eliminación compatible del servicio en el que almacena los datos. Esto se puede lograr mediante el uso de una API de "eliminación" o mediante la implementación de un mecanismo de "tiempo de vida".
Eliminar punteros a objetos de Amazon S3 y dejar huérfanos de datos en la cuenta de servicio no son acciones de eliminación aceptables.
Métodos aceptables para la destrucción de datos de Amazon
Esta sección proporciona una descripción general de los métodos aceptables para destruir datos de Amazon.
- Limpiar: esta operación hace que los datos de un dispositivo sean ilegibles a través de "ataques de teclado", lo que significa que un usuario utiliza aplicaciones forenses pero no técnicas de laboratorio. Una operación de borrado puede implicar una o más pasadas de sobrescritura del dispositivo, comandos de borrado de firmware u otros métodos como se define en NIST SP800-88r1 .
- Purga: esta operación hace que los datos de un dispositivo sean ilegibles mediante técnicas de recuperación de laboratorio. Una operación de purga puede implicar comandos avanzados de borrado de firmware, codificación de claves en unidades de autocifrado u otros métodos como se define en NIST SP800-88r1 .
- Destrucción física: esta categoría, como se describe en las siguientes subsecciones, puede incluir trituración, pulverización, trituración, incineración y desmagnetización. Hace que los datos del dispositivo sean irrecuperables y el propio dispositivo inutilizable.
- Desmagnetización: aplica un campo magnético con la fuerza suficiente para superar la coercitividad magnética de los medios magnéticos. Esto solo es efectivo en medios magnéticos, y la coercitividad de los medios varía entre modelos y fabricantes. Los desarrolladores deben obtener información directamente del fabricante para calibrar correctamente un desmagnetizador para un dispositivo determinado.
- Aplastamiento: Aplicar una gran fuerza de compresión a un dispositivo para destruirlo.
- Pulverizar: Reducir un dispositivo a partículas pequeñas.
- Trituración: Cortar los medios en partes pequeñas que no se pueden volver a ensamblar. Para lograr la máxima eficacia, las partes cortadas deben ser más pequeñas que el área física requerida para almacenar un bloque de datos.
- Incinerar: aplicar calor extremo a un dispositivo para destruirlo quemándolo o derritiéndolo. Calentar más allá del punto de Curie de los medios magnéticos (la temperatura máxima que puede alcanzar un material antes de perder o cambiar sus propiedades magnéticas) también es efectivo.
Conclusión
La gestión del ciclo de vida de los datos es una parte importante de la protección de los datos. Todos los datos, especialmente la PII, deben tener términos definidos sobre la duración del almacenamiento, el uso y la destrucción. Practicar una buena higiene de los datos a través de la retención y el mantenimiento de los datos durante el tiempo que se necesiten y la destrucción cuando no se necesiten ayuda a limitar el radio de explosión o la cantidad de datos expuestos durante un incidente de seguridad. Algunas autoridades y organismos reguladores tendrán estándares definidos sobre cuánto tiempo una organización debe retener los datos, pero incluso sin estos estándares, aún debe definir cuánto tiempo se retienen los datos. Como sucede de manera similar con otros activos, cuanto más tiempo mantenga los datos "por si acaso" se necesitan, aumentarán más los costos asociados con los medios de almacenamiento, las ubicaciones para almacenarlos y la capacitación del personal sobre el manejo adecuado.
Recursos adicionales
- Guía para desarrolladores de Amazon S3 Glacier
- Configuración de un archivo compatible en AWS
- Interactúe con los partners de AWS: encuentre un partner de APN de AWS
- Política de protección de datos de Amazon MWS y SP-API
- Política de uso aceptable de Amazon MWS y SP-API
Referencias de la industria
- Publicación especial NIST 800-88 Revisión 1: Directrices para la desinfección de medios
- NIST 800-53 Rev.5: Controles de seguridad y privacidad para sistemas de información y organizaciones
Revisiones de documentos
| Fecha | Descripción |
|---|---|
| diciembre 2022 | Revisado para precisión técnica. |
| enero 2020 | Primera publicación |
Avisos
Los sellers y desarrolladores de Amazon son responsables de realizar su propia evaluación independiente de la información de este documento. Este documento: (a) es solo para fines informativos, (b) representa las prácticas actuales, que están sujetas a cambios sin previo aviso, y (c) no crea ningún compromiso ni garantía por parte de Amazon.com Services LLC (Amazon) y sus afiliados, vendors o licenciantes. Los productos o servicios de Amazon Marketplace Web Services (Amazon MWS) y Amazon Selling Partner API (Amazon SP-API) se proporcionan "tal cual" sin garantías, representaciones o condiciones de ningún tipo, ya sean expresas o implícitas. Las responsabilidades y obligaciones de Amazon con respecto a Amazon MWS y SP-API están controladas por los acuerdos MWS y SP-API de Amazon (incluido el Acuerdo de desarrollador de Selling Partner API de Amazon o el Acuerdo de licencia de Selling Partner API de Amazon), y este documento no es parte de, ni modifica ningún acuerdo entre Amazon y ninguna de las partes.
© 2022 Amazon.com Services LLC o sus afiliados. Reservados todos los derechos.
Updated almost 3 years ago