Protección de aplicaciones de Amazon SP-API: Respuesta ante incidentes
Cómo proteger las aplicaciones de Amazon SP-API
Descripción general
Este documento técnico brinda orientación sobre lo que constituye un plan de respuesta a incidentes y los mecanismos necesarios para manejar un incidente. Tener un plan de respuesta a incidentes bien documentado ayuda a las organizaciones a identificar, detectar y responder rápidamente a las fallas en la gestión de riesgos. El plan debe revisarse periódicamente, revisarse para facilitar el manejo inmediato de incidentes en caso de que ocurra, e incorporar las lecciones aprendidas.
Requisitos de la política de protección de datos
Como requisito, los desarrolladores deben crear y mantener un plan para detectar y manejar incidentes de seguridad. Dichos planes deben identificar las funciones y responsabilidades de respuesta a incidentes, definir los tipos de incidentes que pueden afectar a Amazon, definir los procedimientos de respuesta a incidentes para los tipos de incidentes definidos y definir una ruta y procedimientos de escalamiento para escalar los incidentes de seguridad a Amazon. Los desarrolladores deben revisar y verificar el plan cada seis meses y después de cualquier cambio importante en la infraestructura o el sistema. Los desarrolladores deben investigar cada incidente de seguridad y documentar la descripción del incidente, las acciones correctivas y los controles del sistema/proceso correctivo asociados implementados para evitar que se repita en el futuro (si corresponde). Los desarrolladores deben mantener la cadena de custodia de todas las pruebas o registros recopilados, y dicha documentación debe ponerse a disposición de Amazon a pedido (si corresponde).
Los desarrolladores deben informar a Amazon (por email a [email protected]) dentro de las 24 horas posteriores a la detección de cualquier incidente de seguridad. Los desarrolladores no pueden notificar a ninguna autoridad reguladora, ni a ningún cliente, en nombre de Amazon, a menos que Amazon solicite específicamente por escrito que el desarrollador lo haga, a menos que lo exija la ley. Amazon se reserva el derecho de revisar y aprobar la forma y el contenido de cualquier notificación antes de que se proporcione a cualquier parte, a menos que dicha notificación sea requerida por ley, en cuyo caso Amazon se reserva el derecho de revisar la forma y el contenido de cualquier notificación antes de que sea proporcionado a cualquier parte. Los desarrolladores deben informar a Amazon dentro de las 24 horas cuando se buscan sus datos en respuesta a un proceso legal o por la ley aplicable.
Respuesta al incidente
Los desarrolladores deben comprender los procesos de seguridad incident response (IR), y el personal de seguridad debe saber cómo responder a los problemas de seguridad. Los desarrolladores sin un equipo de seguridad dedicado deben 1) asegurarse de que una parte de la organización esté suficientemente capacitada y equipada con herramientas para realizar tales actividades y/o 2) considerar establecer uno. Los desarrolladores que deseen crear un equipo de seguridad maduro deben considerar esta mejor práctica: integrar el flujo de eventos y hallazgos de seguridad en un sistema de notificación y workflow. Dichos sistemas incluyen sistemas de emisión de boletos, un sistema de errores/problemas u otro sistema de gestión de eventos e event management (SIEM).
Los desarrolladores deben comenzar poco a poco, desarrollar runbooks, aprovechar las capacidades funcionales y crear una biblioteca de mecanismos de respuesta a incidentes para iterar y mejorar. Esto debe incluir equipos que no estén involucrados con la seguridad, incluido el departamento legal. De esta forma, los desarrolladores comprenderán el impacto que tiene IR en los objetivos comerciales.
Los desarrolladores deberían considerar el uso de lineamientos de la industria como NIST’s SP 800-61R2: Computer Security Incident Handling Guide Esta guía del NIST incluye una lista de verificación que proporciona los principales pasos a realizar durante un incidente. Los desarrolladores deben considerar el uso de la lista de verificación como plantilla al desarrollar un plan. Pueden desarrollar un plan específico para reflejar las funciones, los objetivos, los riesgos y las acciones de mitigación de la organización. Cada uno de estos depende del tamaño y la complejidad de la organización y sus sistemas.
A lo largo de este documento técnico, nos referiremos a los Controles de seguridad y privacidad para sistemas de información y organizaciones del National Institute of Standards and Technology’s (NIST) de los Estados Unidos (Special Publication 800-53 Revision 5), comúnmente denominado NIST 80053 como referencia. Este marco en desarrollo proporciona controles flexibles para proteger a las organizaciones de las amenazas a la seguridad y la privacidad. Los desarrolladores deben considerar el uso de este marco para implementar y fortalecer sus controles organizacionales.
Fundamento de la respuesta a incidentes
Los planes de respuesta a incidentes, a menudo denominados procedimientos o runbooks, definen los pasos para investigar y remediar un incidente. La experiencia y la educación son vitales para implementar un programa de respuesta a incidentes antes de manejar un evento de seguridad.
Un evento es cualquier ocurrencia en un sistema o red, que va desde eventos aceptables (p. ej., un usuario conocido que inicia sesión en una computadora) hasta un evento adverso (p. ej., un usuario desconocido que inicia sesión en una computadora). Dichos eventos adversos pueden provocar un incidente, como una violación de las políticas de seguridad informática, las políticas de uso aceptable o los requisitos contractuales.
Los desarrolladores que deseen utilizar NIST 800-53 para establecer un plan IR pueden examinar la sección IR-8: Incident Response Plan . IR-8 detalla los componentes necesarios para implementar un plan IR. Dichos componentes incluyen:
• Definición de los recursos y apoyo de gestión necesarios.
• Revisar y aprobar el plan con una cadencia definida.
• Designar la responsabilidad de RI al personal apropiado.
A medida que los desarrolladores implementen este control, pueden lograr el cumplimiento de los requisitos de Amazon DPP. Esto incluye revisar y verificar el plan cada seis meses e informar a Amazon dentro de las 24 horas posteriores a la detección de cualquier incidente.
Eventos de seguridad
Un plan de respuesta a incidentes bien definido incluye mecanismos de respuesta para diferentes tipos de eventos de seguridad. Los desarrolladores deben considerar el uso de diagramas para mapear la relación entre las amenazas y los mecanismos de respuesta apropiados. Por ejemplo, la ventana de Johari, creada en 1955 por Joseph Luft y Harrington Ingham, es una cuadrícula que consta de cuatro cuadrantes, como se muestra a continuación:
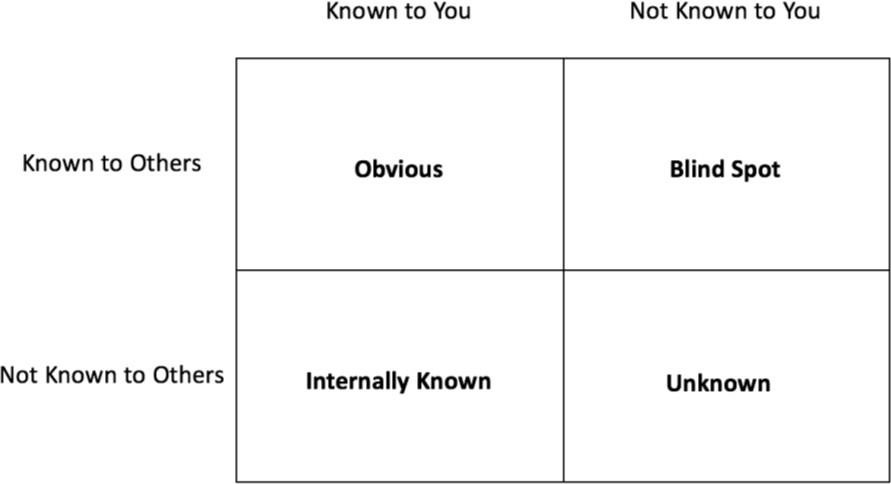
Figura 1 – Ventana de Johari
Tipos de eventos de seguridad
Aunque la Ventana de Johari no fue diseñada para la seguridad de la información, puede ayudar a los desarrolladores a comprender cómo evaluar las amenazas de una organización. En el concepto basado en la respuesta a incidentes, los cuatro cuadrantes son: amenazas obvias, internamente conocidas, de punto ciego y desconocidas. Para cada tipo de incidente, los desarrolladores deben definir procedimientos de respuesta a incidentes para verificar que estén adecuadamente preparados para responder. A medida que los desarrolladores definen esos tipos, deben considerar las amenazas relevantes tanto para los partners como para los vendors. Incluya información de contacto e identifique el punto en el que las herramientas y los sistemas notifican al personal dentro de la organización. Esto es necesario para cumplir con los acuerdos de nivel de servicio en las obligaciones regulatorias y contractuales, incluso con Amazon.
Obvio
Las amenazas obvias son riesgos de los que tanto los desarrolladores como sus partners, como Amazon, son conscientes. Por ejemplo, los actores malintencionados suelen emplear ataques de denegación de servicio (DoS) contra organizaciones. En un ataque DoS, un actor malicioso interrumpe temporal o indefinidamente la capacidad de la aplicación para conectarse a Internet. los desarrolladores deben emplear mecanismos para proteger los servicios de interrupciones maliciosas intencionales. Los desarrolladores deben considerar la definición de objetivos de recuperación de tiempo de inactividad mínimamente aceptables para los ataques DoS.
Los actores malintencionados comúnmente intentan invadir, e incluso controlar, las organizaciones al entrometerse en sus aplicaciones. Los desarrolladores pueden mitigar los intentos de intrusión mediante la implementación de Intrusion Prevention Systems (IPS) y Intrusion Detection Systems (IDS). Cada sistema examina los flujos de tráfico de la red para detectar si un intruso está intentando acceder al sistema. En el caso de una IPS, el sistema impide el ingreso de usuarios no autorizados. Sin embargo, si una intrusión tiene éxito, un IDS enviará una notificación para activar una respuesta.
Conocido internamente
Las amenazas conocidas internamente son aquellas con las que el desarrollador está familiarizado, pero sus partners (como Amazon) no. Esto incluye experiencia interna o conocimiento institucional. Por ejemplo, el equipo de desarrollo puede tener prácticas no documentadas pero establecidas para administrar los cambios de configuración. Sin embargo, existen riesgos en tener un proceso indocumentado. Por ejemplo, el equipo:
- Es posible que no esté seguro de que todos los cambios se prueben y aprueben.
- Es posible que no tenga mecanismos de reversión en caso de que las versiones de código no funcionen según lo previsto.
- Es posible que no busque errores en las nuevas versiones de producción.
Los desarrolladores deben considerar estos escenarios para mitigar las amenazas conocidas internamente.
Además, los riesgos internos, como la acción malintencionada o involuntaria de un empleado, pueden dañar el medio ambiente. Los controles de gestión de acceso y los mecanismos de prevención de pérdida de datos ayudan a prevenir y detectar tales acciones. Limitar el acceso no autorizado a los datos, tanto de entidades internas como externas, es un paso fundamental para asegurar y proteger los datos. Los desarrolladores deben emplear el principio de privilegio mínimo, otorgando solo el acceso necesario para que una persona o programa complete su tarea. Es una buena práctica eliminar las cuentas de acceso predeterminadas y limitar el uso de cuentas compartidas. Si es necesario, los desarrolladores deben monitorear las cuentas compartidas para validar que solo se usen cuando sea necesario. Las cuentas compartidas solo deben compartirse después de que los administradores correspondientes aprueben su uso. Los desarrolladores pueden complementar estos monitores con controles de prevención de pérdida de datos. Esto evita el intercambio involuntario de información confidencial o crítica con partes no autorizadas. Esa información puede incluso incluir claves de cifrado o credenciales de aplicaciones (p. ej., incrustadas en el código y expuestas en GitHub) que pueden eludir los controles.
Punto ciego
Los puntos ciegos son riesgos con los que un partner está familiarizado, pero el desarrollador no. Un partner con la experiencia adecuada puede compartir ese conocimiento. Dichos riesgos pueden ser vulnerabilidades y exposiciones comunes (CVE) que afectan a las aplicaciones sin el conocimiento del propietario. Aunque los desarrolladores pueden estar familiarizados con esos riesgos en el cuadrante obvio, un partner podría recomendar controles y soluciones con los que el desarrollador no está familiarizado. Además, un partner puede estar equipado para identificar controles ajustados para mitigar los riesgos en el cuadrante conocido internamente.
Otros puntos ciegos incluyen el entorno regulatorio cambiante. El Reglamento General de Protección de Datos (GDPR) de la Unión Europea afecta a las empresas de todo el mundo, y están surgiendo rápidamente reglamentos similares, como la Ley de Privacidad del Consumidor de California (CCPA). Tales regulaciones pueden afectar los mecanismos de respuesta y los métodos de notificación.
El monitoreo del entorno externo ayuda a mitigar estos riesgos. Específicamente, las bases de datos nacionales de vulnerabilidades (NVD) ayudan a las organizaciones a comprender las últimas vulnerabilidades y sus puntajes de riesgo. Dichos puntajes, liderados por el Sistema de puntaje de vulnerabilidad común (CVSS), enumeran la gravedad de un error, teniendo en cuenta su complejidad e impacto. Los desarrolladores deben mantenerse al tanto de las actualizaciones de la industria, los cambios normativos y los requisitos contractuales. Los requisitos cambian con frecuencia y pueden requerir que los desarrolladores mejoren los procesos internos para seguir cumpliendo. Los desarrolladores deben reunirse con los partners regularmente para comprender los puntos ciegos y mitigarlos. Mientras miden la mejora, los desarrolladores pueden considerar ponerse en contacto con Amazon, a través de la página de soporte de servicios de Amazon, para obtener asesoramiento experto sobre cómo proteger su aplicación Amazon SP-API.
Desconocido
Las amenazas desconocidas son riesgos con los que ni los desarrolladores ni sus partners están familiarizados. La implementación y revisión de los mecanismos de monitoreo pueden identificar indicadores de eventos de seguridad.
Indicadores de eventos de seguridad
Los desarrolladores deben investigar todos los eventos de seguridad para asegurarse de que no se conviertan en incidentes de seguridad. Aunque no es exhaustiva, los desarrolladores deben considerar la siguiente lista de posibles indicadores de eventos de seguridad:
- Registros y monitores . Un cambio repentino en la actividad informática, como lo indican las herramientas de monitoreo y los registros, puede indicar un evento de seguridad.
- Actividad de facturación inusual . Un aumento repentino en la actividad de facturación puede indicar un evento de seguridad. Esta actividad de facturación puede surgir de procesos intensivos en computación que podría iniciar un intruso, como la minería de bitcoin.
- Fuentes de inteligencia de amenazas . Si su organización se suscribe a una fuente de inteligencia de amenazas de terceros, correlacione esa información con otras herramientas de registro y monitoreo para identificar posibles indicadores de eventos.
- Integridad de datos . Los datos en un servicio o aplicación devuelven valores inesperados.
- Exposición de datos . Los datos confidenciales están expuestos a partes no autorizadas o no deseadas.
- Falta de disponibilidad . Una aplicación o servicio no puede cumplir con sus funciones.
- Mecanismo de contacto de seguridad orientado al público . Un método bien conocido y publicitado para ponerse en contacto con el equipo de seguridad puede informar a los desarrolladores sobre un incidente. Los clientes, el equipo de desarrollo u otro personal pueden notar e informar algo inusual. Es posible que los desarrolladores que trabajan con el público en general deban desarrollar un mecanismo de contacto de seguridad público, como una dirección de email de contacto o un formulario web.
- Alertas del sistema . Los sistemas internos pueden generar notificaciones que alertan en caso de actividades inusuales, maliciosas o costosas. Por ejemplo, los desarrolladores pueden crear una notificación para actividades que ocurren fuera de los plazos previstos.
- Aprendizaje automático . Los desarrolladores pueden aprovechar el aprendizaje automático para identificar anomalías complejas para una organización específica o una persona individual. Los desarrolladores pueden perfilar las características normales de las redes, usuarios y sistemas para ayudar a identificar comportamientos inusuales.
Definir roles y responsabilidades.
Las habilidades y los mecanismos de respuesta a incidentes son vitales cuando se manejan eventos nuevos o de gran escala. El manejo de eventos de seguridad poco claros requiere disciplina interorganizacional, sesgo para la acción decisiva y la capacidad de generar resultados.
Los desarrolladores deben trabajar con las partes interesadas, el asesoramiento legal y el liderazgo de la organización para identificar objetivos al responder a un incidente. Algunos objetivos comunes incluyen contener y mitigar el problema, recuperar los recursos afectados, preservar los datos para el análisis forense y la atribución. Los desarrolladores deben considerar estos roles y responsabilidades, y si deben participar terceros.
Aquí hay una lista de las partes interesadas en la seguridad:
- Propietarios de aplicaciones . Es posible que los desarrolladores deban ponerse en contacto con los propietarios de las aplicaciones o los recursos afectados porque son subject matter experts (SMEs) que pueden proporcionar información y contexto. Es posible que se requiera que los propietarios de aplicaciones o las PYME actúen en situaciones en las que el entorno no sea familiar, tenga una complejidad imprevista o en las que los respondedores no tengan acceso. Las PYMES deben practicar y sentirse cómodas trabajando con el equipo de RI.
- seguridad de la información El equipo de Seguridad de la Información será el principal punto de contacto una vez que se identifique un evento o incidente. Pueden responder investigando, remediando y previniendo que ocurran incidentes.
- legales El equipo Legal brinda orientación para comprender cualquier impacto legal que pueda tener un incidente de seguridad. Esto incluye la elaboración de comunicaciones para todas las partes afectadas, incluidos los contratistas, los vendors de servicios, los clientes y las autoridades reguladoras.
- Directores de Negocios y Seguridad de la Información . El liderazgo en seguridad de la información, incluido el Chief Information Security Officer (CISO), deberá mantenerse al tanto de la salud de la seguridad del desarrollador. En coordinación con los equipos Legal y de Seguridad de la Información, el CISO lidera la organización para prevenir, detectar, remediar y comunicar la respuesta a incidentes de acuerdo con las leyes y las mejores prácticas.
- El resto de la organización. La organización en general debe ser consciente de los riesgos potenciales y de los mecanismos de notificación apropiados. La capacitación en concientización sobre la seguridad de la información puede ayudar al personal (técnico y no técnico) a evitar que ocurran eventos de seguridad, identificar indicadores de incidentes e informar incidentes potenciales al equipo de seguridad.
- Terceros . Los partners de confianza pueden ayudar en la investigación y la respuesta, brindando experiencia adicional y un escrutinio valioso. Dichos partners incluyen a terceros que requieren por contrato la notificación de que ocurrió un incidente. Específicamente, Amazon requiere que los desarrolladores reporten a Amazon, por email a [email protected], dentro de las 24 horas posteriores a la detección de cualquier incidente de seguridad. Alternativamente, los vendors de servicios pueden incluir términos y condiciones para las áreas de seguridad de la información de las que son responsables. Dichos vendors o partners pueden incluir Cloud Service Providers (CSPs) que poseen una parte de las responsabilidades de seguridad dentro del entorno. La Figura 2 muestra una representación típica del modelo de responsabilidad compartida tal como se aplica a AWS. AWS posee la seguridad DE la nube y proporciona los niveles más altos de seguridad posibles. Sus clientes son responsables de la seguridad de sus recursos en la nube, manteniendo su contenido seguro y compatible.
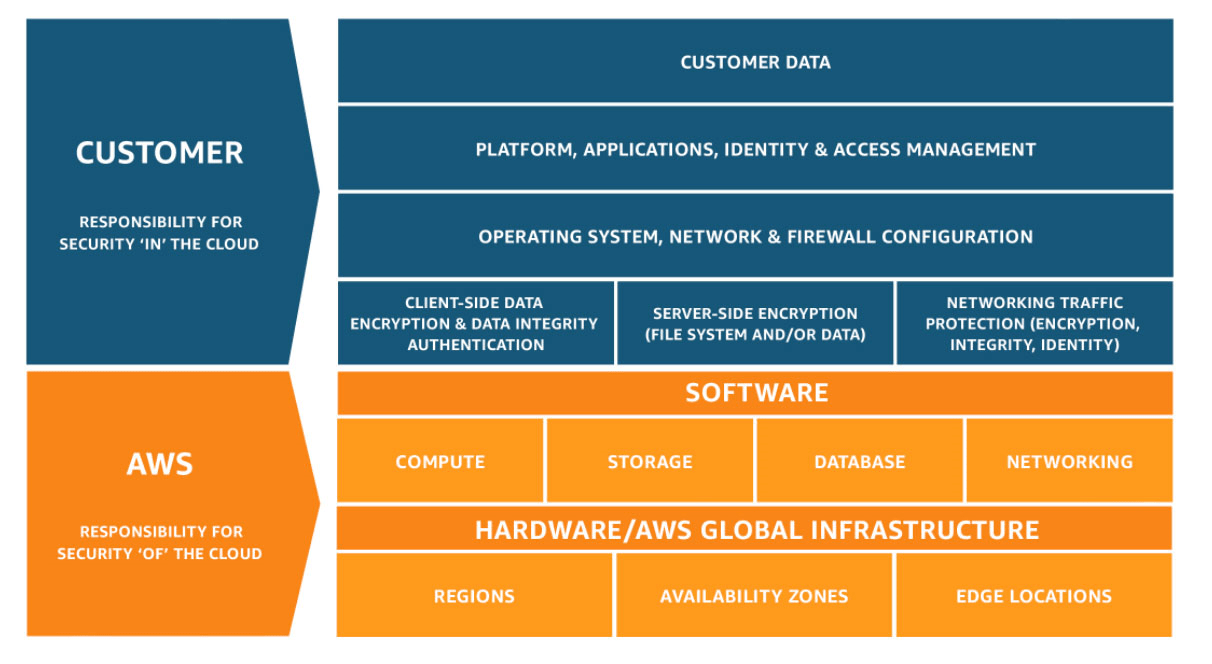
Figura 2: Modelo de responsabilidad compartida de AWS
Notificación y respuesta
Las partes apropiadas, como Amazon, deben recibir una notificación de un evento que ocurra para que puedan responder de acuerdo con los procesos. De lo contrario, el evento pasará desapercibido y causará un mayor daño a los sistemas.
Los desarrolladores deben implementar sistemas de monitoreo que puedan alertar automáticamente después de que ocurra un evento. Los mecanismos de notificación comunes incluyen correos electrónicos, sistemas de emisión de boletos, buscapersonas, alarmas y servicio de mensajes cortos (SMS). Los desarrolladores deben tener suficientes herramientas para responder al incidente de acuerdo con los objetivos de respuesta.
Los desarrolladores deben implementar patrones de respuesta cuando ocurre el evento. Documentar un incidente es crucial. Esto conserva la información relevante, como la descripción del incidente, las acciones correctivas y los controles implementados para ayudar a prevenir futuras recurrencias. Según el DPP de Amazon, los desarrolladores deben documentar la descripción del incidente, las acciones de remediación y los controles del sistema/proceso correctivo asociados implementados para evitar que se repita en el futuro, si corresponde. Además, la creación de documentación ayuda a escalar el problema a las partes interesadas internas, los partners y las partes afectadas.
Los desarrolladores que utilizan NIST 800-53 pueden consultar IR-4: Manejo de incidentes. Una respuesta eficaz a incidentes significa manejar un incidente de acuerdo con las mejores prácticas y los planes internos. Los planes de manejo de incidentes y respuesta a incidentes están interconectados. Cada uno apoya al otro a medida que los desarrolladores fortalecen sus capacidades de respuesta y manejo de incidentes. Control IR-4 es compatible con esto, y seguir cada parte del control ayudará a los desarrolladores a cumplir con Amazon DPP. Si bien no es obligatorio, recomendamos que los desarrolladores consideren implementar las mejoras de control en este dominio. Estas mejoras ayudan a los desarrolladores a estar bien equipados para responder a diferentes tipos de incidentes y certificar la salud y el éxito de sus operaciones.
NIST control IR-6: Incident Reporting ayuda a definir el personal en una ruta de escalada. Esta es la cadena de personas que deben permanecer informadas en caso de que ocurra un incidente. Los desarrolladores deben definir una ruta de escalada para que las partes interesadas críticas y los asesores legales permanezcan informados sobre un incidente y puedan ayudar al equipo de seguridad a tomar medidas. Las partes interesadas relevantes permanecerán informadas del incidente, sus efectos y su estado, todo lo cual es necesario en caso de que el desarrollador esté legal o contractualmente obligado a notificar a una parte externa. Los desarrolladores deben comprender los requisitos legales y contractuales para informar un incidente, a quién y cuándo. De manera similar, los desarrolladores deben desarrollar objetivos para cumplir con esos requisitos. Los desarrolladores deben verificar que la ruta de escalada y los procedimientos de notificación incluyan a todas las partes con derecho legal o contractual a saber.
Los desarrolladores deben validar que la ruta de escalada y los procedimientos de notificación incluyan a todas las partes con derecho legal o contractual a saber. Por ejemplo, el RGPD exige que los controladores de datos notifiquen a la autoridad de control correspondiente dentro de las 72 horas posteriores a la verificación de que se han producido ciertos tipos de violaciones de datos personales. De manera similar, la Política de protección de datos de Amazon requiere que los desarrolladores reporte a Amazon (por email a [email protected]) dentro de las 24 horas posteriores a la detección de un incidente.
Preservar evidencia
Los desarrolladores deben verificar que recopilan, almacenan y protegen registros que capturan todas las acciones críticas dentro del entorno. Como mínimo, estos registros deben contener:
- El éxito o fracaso del evento.
- La fecha y la hora.
- Intentos de acceso.
- Cambios de datos.
- Errores del sistema.
Los desarrolladores con acceso a la información de Amazon deben asegurarse de que los registros no contengan información de identificación personal. Los registros deben conservarse durante al menos 90 días como referencia en caso de un incidente de seguridad.
Los desarrolladores deben proteger los registros de eliminaciones accidentales o intencionales almacenándolos en una ubicación segura con acceso otorgado solo al personal requerido. La información de registro es vital para comprender qué, cómo y cuándo se comprometió un sistema. Los desarrolladores deben conservar los registros, las unidades y otras pruebas copiándolos en una cuenta centralizada.
Los desarrolladores deben desarrollar y mantener una cadena de custodia para mantener la integridad de la información registrando quién accedió a la información, a quién se le entregó y todas las acciones realizadas. Estas prácticas brindan a los desarrolladores la capacidad de afirmar si los sistemas afectados fueron alterados y garantizar que los hallazgos de la investigación sean precisos. Los desarrolladores que siguen el marco NIST 800-53 pueden consultar el control AU-10(3): NonRepudiation | Cadena de Custodia . Si bien Auditoría y Responsabilidad (AU) no está dentro del dominio IR, este control puede ayudar a definir y mantener un proceso de cadena de custodia. Además de mantener el cumplimiento de Amazon DPP, una cadena de custodia puede ayudar a tomar medidas contra un intruso en un tribunal de justicia, si es necesario.
Los desarrolladores que deseen obtener más información sobre el registro y la supervisión deben leer el documento técnico sobre el registro y la supervisión de Amazon SP-API para comprender cómo implementar registros compatibles.
Revisión continua
Los desarrolladores deben probar, revisar y actualizar periódicamente su plan de respuesta a incidentes. De lo contrario, los desarrolladores no estarán equipados para responder y resolver rápidamente los incidentes de seguridad. Amazon requiere que los desarrolladores revisen y verifiquen el plan cada seis meses y después de cualquier cambio importante en la infraestructura o en el sistema. Dichos cambios pueden incluir:
- sistema Los cambios en el sistema, como el desarrollo de software nuevo, el uso de herramientas nuevas o el desuso de herramientas existentes, pueden aumentar la probabilidad de problemas potenciales.
- controles La implementación de nuevos controles o la experimentación de fallas en los controles pueden afectar la exposición del desarrollador.
- Entornos operativos . Cambiar de entornos locales a entornos en la nube, o viceversa, puede introducir nuevas complejidades en los sistemas. Los desarrolladores deben realizar evaluaciones de riesgos para comprender los nuevos riesgos que puede presentar dicho cambio.
- cadena de suministro Los cambios en la cadena de suministro, como cambiar de vendor de hardware o cambiar de empresa contratista, pueden introducir nuevos riesgos. Por ejemplo, es posible que un vendor de hardware en particular reporte rápidamente a sus clientes sobre los parches de errores, pero es posible que un competidor de menor costo no ofrezca ese servicio. En este caso, los clientes de este último deben tener en cuenta el hecho de que necesitarán proteger activamente su infraestructura contra vulnerabilidades web comunes como la inyección de SQL e implementar esos parches.
- Niveles de riesgo . Los niveles de riesgo fluctúan debido a los factores antes mencionados. Los desarrolladores deben considerar implementar un nivel de riesgo aceptable para el negocio y revisar el plan de respuesta a incidentes si ese riesgo alcanza su umbral.
Las revisiones frecuentes también son valiosas. Si los desarrolladores identifican brechas en los procesos o herramientas durante las operaciones normales, deben planear solucionarlas. Estas brechas pueden ser autoidentificadas o pueden ocurrir después de un cambio o incidente importante en el sistema. Los desarrolladores deben implementar procesos y controles correctivos para detectar y prevenir futuros incidentes. Posteriormente, los desarrolladores deben actualizar el plan de respuesta a incidentes para reflejar las lecciones aprendidas y los procesos implementados.
Después de diseñar y construir el plan de respuesta a incidentes, los desarrolladores deben probarlo antes de que ocurra un evento real. Los desarrolladores deben establecer una frecuencia en la que el equipo de seguridad simule un incidente de seguridad y pruebe los procesos en consecuencia. Las simulaciones son métodos seguros para encontrar vectores de riesgo y mejorar los controles y procesos. Las simulaciones también cumplirán con el requisito de Amazon de revisar y verificar el plan de respuesta a incidentes cada seis meses.
Para cada escenario descrito, los desarrolladores deben actualizar el plan de respuesta en consecuencia y notificar a las partes interesadas si surge algún cambio.
Recursos adicionales
- Descripción general de la API de SP de Amazon
- Política de uso aceptable de Amazon
- Política de protección de datos de Amazon
- Modelo de responsabilidad compartida de AWS
- Guía de respuesta a incidentes de seguridad de AWS
Referencias de la industria
- NIST SP 800-61R2: Guía de manejo de incidentes de seguridad informática
- NIST 800-53 Rev.5 (Borrador): Controles de seguridad y privacidad para sistemas de información y organizaciones
- Base de datos de vulnerabilidad nacional (NVD)
- Sistema de puntuación de vulnerabilidad común (CVSS)
Revisiones de documentos
| Fecha | Descripción |
|---|---|
| septiembre 2022 | Segunda publicación |
| enero 2020 | Primera publicación |
Avisos
Los sellers y desarrolladores de Amazon son responsables de realizar su propia evaluación independiente de la información de este documento. Este documento: (a) es solo para fines informativos, (b) representa las prácticas actuales, que están sujetas a cambios sin previo aviso, y (c) no crea ningún compromiso ni garantía por parte de Amazon.com Services LLC (Amazon) y sus afiliados. , vendor o licenciantes. Los productos o servicios de Amazon SP-API se proporcionan "tal cual" sin garantías, representaciones o condiciones de ningún tipo, ya sean expresas o implícitas. Este documento no forma parte ni modifica ningún acuerdo entre Amazon y ninguna de las partes.
© 2022 Amazon.com Services LLC o sus afiliados. Reservados todos los derechos.
Updated almost 3 years ago